八股文
printf("%s = %d \n", "1+1", 1+1);
// 1+1 = 2编程语言相关
声明&定义
声明:声明是向编译器表明某个标识符(如变量、函数、类等)的存在,并告知编译器该标识符的类型和使用方式,但并不为其分配内存空间。
定义:定义不仅要声明标识符的类型和使用方式,还要为其分配内存空间(对于变量)或者提供具体的实现(对于函数和类)。
声明可以多次进行,只要保证类型一致即可; 定义在一个程序中通常只能进行一次,否则会导致重复定义的错误。
include<>和""的区别
<>从标准库路径搜索
”“从用户工作路径搜索
函数指针&指针函数
函数指针:是指针,指向函数。详细见函数指针
int add(int a, int b)
{ return a+b; }
int plus(int a, int b)
{ return a*b; }
int main()
{
int (*p)(int, int) = &add;
int (*p)(int, int) = plus;
}指针函数:是函数,其返回值是指针
int c
int* func(int a, int b)
{
c = a+b;
return &c;
}数组指针&指针数组
数组指针:是指针,指向数组的起始地址。
// 定义一个数组
int arr[5] = {1, 2, 3, 4, 5};
// 数据类型 (*指针名)[数组大小];
int (*ptr)[5] = &arr;
for (int i = 0; i < 5; i++)
{
printf("%d ", (*ptr)[i]);
}
// 如果 int (*ptr)[4] = &arr; 则编译会报错指针数组:是数组,里面的元素是指针
int a = 1, b = 2, c = 3;
// 数据类型 *指针名[数组大小];
int* ptr_arr[3] = { &a, &b, &c };指针的大小
指针的大小,和编译器的位数有关,与指针指向的类型无关。因为指针存储的是一个地址,不管你是什么类型的变量或者函数,你在内存中的地址都是固定大小的。
32bit系统,指针4byte,64bit系统,指针8byte。
int a, *b;
double c, *d;
printf("%d %d %d %d", sizeof(a), sizeof(b), sizeof(c), sizeof(d));
// 32位系统 输出 4 4 8 4sizeof&strlen
sizeof:是一个运算符,编译器在编译阶段就可以确定 sizeof 的结果,不需要在程序运行时进行计算。计算的是占用内存的大小。
语法:sizeof(数据类型) 或者 sizeof(表达式)
sizeof(“\0”) = 2 // 字符串“\0”,\0占一个字节,看不到的结束空字符也占一个字节,所以实际是2字节!
strlen:是一个函数,要包含string.h头文件。strlen 函数用于计算以空字符 '\0' 结尾的字符串的实际长度,也就是字符串中字符的个数(不包括终止符 '\0'),需要在程序运行时进行计算.
语法:strlen(字符串指针),它接受一个指向以 '\0' 结尾的字符串的指针作为参数。
char s[] = "1234";
// 输出得到结果
sizeof(s) = 5 // 除了我们看到的1234,还有一个看不到的结束空字符'\0'。实际s占用了5byte的内存
sizeof("\0") = 2 // 字符串“\0”,\0占一个字节,看不到的结束空字符也占一个字节,所以实际是2字节
strlen(s) = 4 // 只统计字符长度,而不是实际占用的内存
/* 需要注意的是,strlen() 函数只能用于计算以空字符 '\0' 结尾的字符串的长度,
如果字符串中没有空字符,则 strlen() 函数的行为是未定义的。 */C语言内存分配方式
静态存储区分配、栈内存分配、堆内存分配
- 静态存储区分配
- 生命周期:在程序的整个运行期间都存在,在程序开始执行时就分配内存,程序结束时才释放内存。
- 分配位置:存储在静态存储区。
- 初始化:如果没有显式初始化,全局变量和静态变量会被自动初始化为 0(对于数值类型)或
NULL(对于指针类型)。
- 适用于那些在程序整个运行周期都需要存在的数据,例如全局变量和静态变量。
-
栈内存分配
- 生命周期:由系统自动分配和释放,当进入一个函数时,函数内的局部变量会在栈上分配内存,函数执行结束后,这些变量所占用的内存会被自动释放。
- 分配位置:存储在栈区,栈内存的分配和释放是由系统自动完成的,遵循后进先出(LIFO)的原则。
- 效率:栈内存的分配和释放速度快,因为只需要移动栈指针。
-
适用于函数内部的局部变量,这些变量只在函数执行期间需要使用。
-
堆内存分配
- 生命周期:需要程序员手动分配和释放,使用
malloc、calloc、realloc 等函数进行内存分配,使用free 函数释放内存。如果忘记释放,会导致内存泄漏。 - 分配位置:存储在堆区,堆内存的分配和释放相对灵活,可以在程序运行过程中根据需要动态分配和释放内存。
- 效率:堆内存的分配和释放速度相对较慢,因为需要进行内存管理操作。
- 生命周期:需要程序员手动分配和释放,使用
-
适用于需要在程序运行过程中动态分配内存的情况,例如创建动态数组、链表等数据结构。
野指针
野指针:指向无效内存地址的指针
可能导致野指针的原因:
1.定义了指针但是未初始化就使用。解决:定义后初始化为NULL
2.free()后未置为NULL
3.指针越界(数组)
宏定义函数
#define 宏名(参数列表) 替换文本
#define MAX(a, b) ((a) > (b) ? (a) : (b))
int x = 10, y = 20;
int max_val = MAX(x, y);宏函数执行效率高,在预处理阶段进行文本替换,不会像普通函数那样有函数调用的开销(如压栈、出栈等操作),因此执行速度更快,尤其适用于简单的、频繁调用的代码片段。
但是他只是简单的文本替换,预处理器不会对参数进行类型检查,所以建议给变量加上括号
如果宏函数被频繁调用,预处理器会在每个调用处进行文本替换,导致生成的代码量增加,可能会使可执行文件变大
define&typedef
define是一个预处理指令,不会做正确性检查,直接进行文本替换
#define 宏名(参数列表) 替换文本
宏定义的作用范围从定义处开始,到文件结束或者使用#undef取消定义为止。宏可以在不同的作用域中重复定义,后定义的会覆盖前面的。
typedef是关键字,会做正确性检查
typedef 已有类型名 新类型名
定义的别名遵循变量的作用域规则
全局变量&静态变量
- 全局变量
- 定义在函数外部的变量,其作用域是整个源程序。如果程序由多个源文件组成,全局变量在其他源文件中可通过
extern关键字声明后使用 - 生命周期是整个程序的运行期间。程序启动时,全局变量被分配内存并初始化;程序结束时,全局变量所占用的内存才会被释放
- 定义在函数外部的变量,其作用域是整个源程序。如果程序由多个源文件组成,全局变量在其他源文件中可通过
- 静态变量
- 静态全局变量
- 定义在函数外部且使用
static关键字修饰,其作用域仅限于定义它的源文件,其他源文件无法访问
- 定义在函数外部且使用
- 静态局部变量
- 定义在函数内部且使用
static关键字修饰,其作用域仅限于定义它的函数内部,但在函数调用结束后,变量的值不会被销毁,下次调用该函数时,静态局部变量会保留上次调用结束时的值
- 定义在函数内部且使用
- 静态全局变量
static作用
- 修饰局部变量:
普通局部变量存放在栈中,函数执行完就会销毁。而被static 修饰的局部变量存储在数据段(已初始化)或 BSS 段(未初始化),在程序的整个运行期间都存在。且只会在第一次调用时进行初始化,之后再调用会保持上一次的值 - 修饰全局变量
默认的全局变量可以在其他c文件中通过extern声明后使用
被static修饰的全局变量无法被其他c文件访问,作用域限定在本c文件。被static修饰的函数同理
内存泄漏
动态内存未释放、指针指向的内存丢失或者被覆盖
内存对齐
现代计算机的内存访问通常是以字(word)为单位进行的,不同的计算机体系结构中,字的大小可能不同,常见的有 4 字节或 8 字节。如果数据没有对齐,处理器可能需要进行多次内存访问才能获取完整的数据。而内存对齐后,处理器可以在一次内存访问中获取到完整的数据,从而提高了内存访问效率。
部分硬件平台要求特定类型的数据必须存放在特定的地址上,否则会引发硬件异常。为了保证程序在不同的硬件平台上都能正常运行,编译器会对数据进行内存对齐处理。
对齐的原则:如果前一个成员的结束地址不是下一个成员对齐值的整数倍,编译器会在它们之间插入填充字节。
struct Example
{
double d; // 8 字节
char c; // 1 字节
int i; // 4 字节
short s; // 2 字节
};
大小为24字节。
占用内存最大的元素d是8字节,所以结构体最终占用空间大小必须是8字节的整数倍
如果前一个成员的结束地址不是下一个成员对齐值的整数倍,编译器会在它们之间插入填充字节。struct Example
{
char c; // 1 字节
short s; // 2 字节
int i; // 4 字节
};
大小为8字节
占用内存最大的元素i是4字节,所以结构体最终占用空间大小必须是4字节的整数倍struct Example
{
char c; // 1 字节
int i; // 4 字节
short s; // 2 字节
};
大小为12字节
占用内存最大的元素i是4字节,所以结构体最终占用空间大小必须是4字节的整数倍指针&数组名
数组名是一个指针常量,它的值是数组首元素的地址,并且这个地址在数组的生命周期内是固定不变的
指针是一个变量,它的值可以被修改,指向不同的内存地址
char arr[5] = { 5,4,3,2,1 };
char *ptr = arr;
for (int i = 0; i < 5; i++)
{
printf("arr = %d ", arr[i]);
printf("arr = %d ", *(ptr+i));
printf("\n");
}
输出结果是相同的区别:
对数组名sizeof,得到的是整个数组占用的字节数
对赋值的指针sizeof,得到的是指针的大小1
指针常量&常量指针
指针常量:是一个常量,这个常量是指针。以通过该指针修改所指向对象的值,不能修改指针指向的地址
// 定义一个指针常量,指向 int 类型
int *const ptr = &a;
// 可以通过指针常量修改所指向对象的值
*ptr = 30;
// 错误:指针常量的值不能改变,不能指向另一个对象
// ptr = &b; 常量指针:是一个指针,这个指针指向常量。不能通过指针修改常量的值,可以修改指针指向的地址
// 定义一个常量指针,指向 int 类型的常量
const int *ptr = &a;
// 错误:不能通过常量指针修改所指向对象的值
// *ptr = 30;
// 指针本身的值可以改变,指向另一个对象
ptr = &b;堆&栈
-
数据存储:
- 栈:主要用于存储局部变量、函数参数、函数调用的上下文信息(如返回地址、寄存器值等)。当函数返回时,对应的栈帧会被自动销毁。
- 堆:用于存储由程序员动态分配的数据,例如使用
malloc 等函数分配的内存。这些数据的生命周期由程序员控制,直到使用free 函数释放为止
-
内存空间大小
- 栈:空间大小通常是有限的,并且在不同的操作系统和编译器中可能会有所不同。
- 堆:空间大小相对较大,理论上可以使用除了系统保留内存和栈空间之外的所有可用内存
-
数据访问效率
- 栈上的数据访问速度较快,因为栈指针的移动是非常高效的,并且栈上的数据通常具有较好的局部性,容易被 CPU 缓存命中
- 堆上的数据访问速度相对较慢,因为堆内存的分配和释放比较复杂,可能会导致内存碎片,并且堆上的数据在内存中的分布可能比较分散,不容易被 CPU 缓存命中
内联函数
// 声明并定义一个内联函数
inline int add(int a, int b) {
return a + b;
}
int main() {
int result = add(3, 5);
std::cout << "Result: " << result << std::endl;
return 0;
}
//当在main函数中调用add(3, 5)时,编译器可能会直接将add函数的代码插入到调用处,
//而不是进行函数调用的常规操作。在常规的函数调用中,程序需要进行一系列操作,如保存当前的执行上下文(包括寄存器的值等)、跳转到函数的代码地址、执行函数体、恢复执行上下文并返回到调用点等,这些操作会带来一定的开销。而内联函数通过在调用处直接展开函数体的代码,避免了这些函数调用的开销,从而提高了程序的执行效率。
如果内联函数的函数体较大,或者在多个地方频繁调用内联函数,会导致代码膨胀,增加程序的内存占用。
当函数的代码量较少,并且在程序中被频繁调用时,使用内联函数可以有效提高程序的性能
嵌入式相关
程序在内存中的各个段
- 代码段(.text段):存储程序的可执行命令,一般是只读的。比如函数体、语句块
- 数据段(.data段):存储已初始化的全局变量、静态变量
- BSS段:存储未初始化的全局变量、静态变量
- BSS 段不占用可执行文件的空间,因为它只记录了变量的大小和位置信息,而不存储实际的数据。只有在程序运行时,系统才会为这些变量分配内存并初始化为 0
- (heap):malloc和free管理的
- (stack):存储局部变量、函数调用的上下文信息
在keil编译完后,会有这样的提示信息:
Program Size: Code=63876 RO-data=1400 RW-data=416 ZI-data=94984
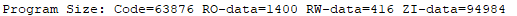
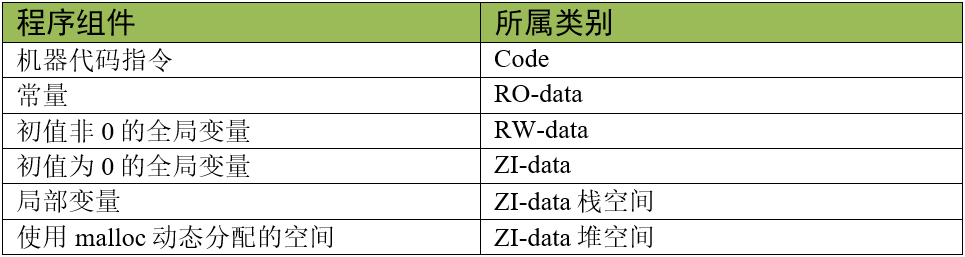
| 程序组件 | 所属类别 | 存储位置 |
|---|---|---|
| 机器代码指令 | Code | ROM区(flash) |
| 常量 | RO-data | ROM区(flash) |
| 初值非0的全局变量、静态变量 | RW-data | RAM区() |
| 初值为0的全局变量、静态变量 | ZI-data | RAM区 |
| 局部变量 | ZI-data栈空间 | RAM区 |
| malloc动态分配的空间 | ZI-data堆空间 | RAM区 |
.c文件如何变成hex或bin文件的
- 预处理:预处理器会依据预处理指令对 C 文件进行处理,比如处理
#include、#define、#ifdef 这类指令。#include头文件插入,#define宏替换,#ifndef等条件编译
- 编译:编译器会把预处理后的 C 代码转化成汇编代码。这个过程会进行语法检查、语义分析、代码优化等操作。生成
.s文件 - 汇编:汇编器会把汇编代码转换为机器码,生成目标文件(通常是
.o 或.obj 格式) - 链接:链接器将多个目标文件以及所需的库文件链接在一起,生成可执行文件
- 最终通过工具转换为hex或bin文件
交叉编译
交叉编译指的是在一个平台(宿主机)上生成另一个平台(目标机)能够运行的可执行代码的过程。判定是否为交叉编译,关键在于看开发环境所在的平台(架构不同或者操作系统不同)和代码运行的目标平台是否一致。 比如我在windows电脑上通过keil5进行stm32开发,就是交叉编译
Footnotes
-
指针的大小,和编译器的位数有关,与指针指向的类型无关。因为指针存储的是一个地址,不管你是什么类型的变量或者函数,你在内存中的地址… ↩